

The term “Data Lake”, “Data Warehouse” and “Data Mart” are often times used interchangbly. But what are exactly the differences between these things? This post attempts to help explain the similarity, the difference and when to use each.
A high-level comparison of these three constructs is as below:
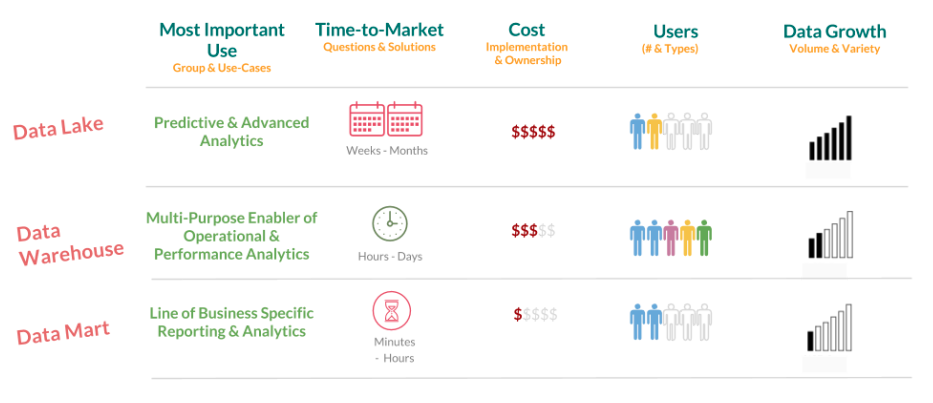
Data Lake
A data lake is the place where you dump all forms of data generated in various parts of your business: structured data feeds, chat logs, emails, images (of invoices, receipts, checks etc.), and videos. The data collection routines does not filter any information out; data related to canceled, returned, and invalidated transactions will also be captured, for instance.
Why data lake?
A data lake is relevant in two contexts:
1. Your organization is so big and your product does so many functions that there are many possible ways to analyze data to improve the business. Thus, you need a cheap way to store different types of data in large quantities.
Eg. Twitter in the B2C space (They have text (Tweets), Images, Videos, Links, Direct Messages, Live Streams, etc.), and Square (B2B) (Transactions, Returns, Refunds, Customer Signatures, Logon IDs etc.).
2. You don’t have a plan for what to do with the data, but you have a strong intent to use it at some point. Thus, you collect data first and analyze later.
Also, the volume is so high that traditional DBs might take hours if not days to run a single query. So, having it in a Massively Parallel Processor (MPP) infrastructure helps you analyze the data comparatively quickly.
Data Warehouse
A data warehouse usually only stores data that’s already modeled/structured.
A Data Warehouse is multi-purpose and meant for all different use-cases. It doesn’t take into account the nuances of requirements from a specific business unit or function. As an example, let’s take a Finance Department at a company. They care about a few metrics, such as Profits, Costs, and Revenues to advise management on decisions, and not about others that Marketing & Sales would care about. Even if there are overlaps, the definitions could be different.
Here are Top 5 Differences between Data Lake and Data Warehouse!
Data Mart is often mistaken with data warehouses, but the two serves completely different purposes, and here is how:
1. Assisting different data types:
A data warehouse usually consists of data that has been extracted from transactional systems and is made up of quantitative metrics and the characteristics that describes them.
A data lake system supports non-traditional data types, like web server logs, sensor data, social network activity, text and images. These non-traditional data sources have largely been ignored like wise, consumption and storing can be very expensive and difficult.
2. User Support:
A data warehouse is an ideal use-case for users who want to evaluate their reports, analyze their key performance metrics or manage data set in a spreadsheet every day. Hence, a data warehouse is ideal for “operational” users, as it is simple and it’s built to meet their needs.
A data warehouse can also support users who do more analysis on data. They use data warehouse as a go-to source for data integration, data preparation and data analytics. Users may also use data warehouse to do deep analysis, which may create totally new data sources based on research. These users are mainly ‘Data Scientists’ and use advanced analytical tools like predictive modeling and statistical analysis.
The data lake system supports all of these users well. Let’s say for example, a data scientists can use their data lake system and work with very large and different data sets that they require, while their business users can make use of a more analytical view of the data provided for their use.
3. Maintaining Data:
During the creation of a data warehouse, a large amount of time will be spent on analyzing data sources and understanding business process and composing data. A large part of this procedure involves making decisions about which data to include and which data to exclude.
However, data lakes maintains ALL data. Not just data that is used today but data that may want to be used someday. Data can also be kept for a long time so that we can go back anytime and want to analyse such data again.
This approach is only possible because of the hardware capability of a data lake, which usually differs from what is used in a data warehouse.
4. Adapting to change:
A good data warehouse design can adapt to change very well, because of the complexity of the data loading process and the work done to make analysis and reporting easy. These changes, however will require plenty of time and resources from such developers.
Many corporations today question the time consumed for the data warehouse team to adapt in their system. This ever increasing time has given rise to the concept of self-service business intelligence.
On the other hand with data lake, as all of the data is stored in a raw form and it’s always accessible to someone who needs to access it. Users are given the power to explore data beyond the capability of exploring data in a data warehouse.
5. Speedy Insights:
This difference is based on the result of the 4 components mentioned above. Data lakes contain all data and data types, which enables users to access data before it has been transformed and structured, this will allow users to get their results faster than a traditional data warehouse approach.
However, this approach may not be as convenient as it sounds. The typical work done by the data warehouse team may not be the same for all of the data sources that is required to do an analysis. This in fact will leave users to explore and use data that they see fit, but a business user may not want to do that work. A business user use-case, is just to get access to reports and KPI’s
With data lake, these operational reports will make use of a more structure view of the data in the data lake, which stimulate what they have always had before in the data warehouse. The difference with this approach is that primarily as metadata which sits over the data in the lake instead of physically rigid tables that require a developer to change.
The Approach you should choose?
That’s a tricky question. If you currently already have a well developed data warehouse, we certainly don’t advice removing it and starting over. However, we certainly advice you to implement a data lake alongside your data warehouse. Your data warehouse can proceed to operate as usual and you can start filling your data lake with new data sources. You can also use it for the collection of your warehouse data that you can roll off and keep it available for your users with access to more data. As your warehouse matures, you can move all your data to your data lake or you may continue the same process. Especially, if you are are starting down the path to build a centralized data platform, it’ll be a better idea to consider both approaches.
Data Mart
While a data-warehouse is a multi-purpose storage for different use cases, a data-mart is a subsection of the data-warehouse, designed and built specifically for a particular department/business function.
Some benefits of using a data-mart:
- Isolated Security: Since the data-mart only contains data specific to that department, you are assured that no unintended data access (finance data, revenue data) are physically possible.
- Isolated Performance: Similarly, since each data-mart is only used for particular department, the performance load is well managed and communicated within the department, thus not affecting other analytical workloads.
3 Types of Data Mart:
1. Dependent Data Marts – A dependent data mart is constructed from an existing data warehouse. It has a top-down approach that begins with storing all your business data in one centralized location, then withdraws a defined portion of the data when needed for analysis.
2. Independent Data Marts – An independent data mart is a stand-alone system, which is created without the use of a data warehouse and focuses on one business function. The data is released from internal or external data sources, refined, then loaded to the data mart, where it is saved until needed or business analysis.
3. Hybrid Data Marts – A hybrid data mart integrates data from a current data warehouse and additional operational source systems. It combines speed and end-user focus of a top-down approach with the assistance of the enterprise-level integration of the bottom up method.
Difference between Data Warehouse and Data Mart:
- Data warehouse is an independent application system whereas a data mart is more specific to support decision application system.
- The data in a data warehouse is stored in a single, centralised archive. Compared to, data mart where data is stored decentrally in different user area.
- A data warehouse consists of a detailed form of data. Whereas, a data mart consists of a summarized and selected data.
- The development of data warehouse involves a top-down approach, while a data mart involves a bottom-up approach.
- A data warehouse is said to be more adjustable, information-oriented and longtime existing. However, with data mart it is said to be restricted, project-oriented and has a shorter existence.
