
在数据仓库领域,有两位大师,一位是“数据仓库”之父 Bill Inmon,一位是数据仓库权威专家 Ralph Kimball,两位大师每人都有一本经典著作,Inmon 大师著作《数据仓库》及 Kimball 大师的《数仓工具箱》,两本书也代表了两种不同的数仓建设模式,这两种架构模式支撑了数据仓库以及商业智能近二十年的发展。今天我们就来聊下这两种建模方式——范式建模和维度建模。
本文开始先简单理解两种建模的核心思想,然后根据一个具体的例子,分别使用这两种建模方式进行建模,大家便会一目了然!
一、两种建模思想
对于 Inmon 和 Kimball 两种建模方式可以长篇大论叙述,但理论是很枯燥的,尤其是晦涩难懂的文字,大家读完估计也不会收获太多,所以笔者根据自己的理解用通俗的语言提炼出最核心的概念。
范式建模
范式建模是数仓之父 Inmon 所倡导的,“数据仓库”这个词就是这位大师所定义的,这种建模方式在范式理论上符合 3NF,这里的 3NF 与 OLTP 中的 3NF 还是有点区别的:关系数据库中的 3NF 是针对具体的业务流程的实体对象关系抽象,而数据仓库的 3NF 是站在企业角度面向主题的抽象。
Inmon 模型从流程上看是自上而下的,自上而下指的是数据的流向,“上”即数据的上游,“下”即数据的下游,即从分散异构的数据源 -> 数据仓库 -> 数据集市。以数据源头为导向,然后一步步探索获取尽量符合预期的数据,因为数据源往往是异构的,所以会更加强调数据的清洗工作,将数据抽取为实体-关系模型,并不强调事实表和维度表的概念。
维度建模
Kimball 模型从流程上看是自下而上的,即从数据集市-> 数据仓库 -> 分散异构的数据源。Kimball 是以最终任务为导向,将数据按照目标拆分出不同的表需求,数据会抽取为事实-维度模型,数据源经 ETL 转化为事实表和维度表导入数据集市,以星型模型或雪花模型等方式构建维度数据仓库,架构体系中,数据集市与数据仓库是紧密结合的,数据集市是数据仓库中一个逻辑上的主题域。
两种建模方式的理论概念就简单介绍到这,因为纯理论知识说再多,大家也可能有点迷惑,所以下面用一个具体的例子来实践两种建模方式。
二、两种建模实践
通过上一小节两种建模核心思想,相信大家对这两种建模方式已经有了大概的理解,接下来我们通过具体的例子,让大家有具体的感受。
以电商举例
大家都网购过,知道购买物品的流程,因此以电商购物为例,更易于大家的理解。
真实的电商购物的流程较复杂,此处表数量和表字段做简化处理。
1. 源表的结构及数据
对于我们大数据平台来说,源表指的电商系统中后台数据库中的表,这种表一般都是 OLTP 类型的表:
① 用户信息表:

② 城市信息表:
③ 用户等级表:
④ 用户订单表:
2. 使用 Inmon 模式建模
使用 Inmon 模式对以上源表数据进行建模,需要将数据抽取为实体-关系模式,根据源表的数据,我们将表拆分为:用户实体表,订单实体表,城市信息实体表,用户与城市信息关系表,用户与用户等级关系表等多个子模块:
① 用户实体表:
(注:ETL 已过滤掉注销用户)

② 支付成功订单实体表:
③ 城市信息实体表:
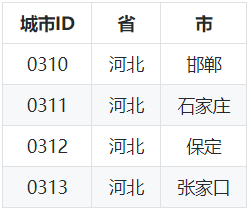
④ 订单与用户关系表:
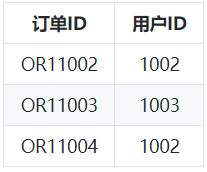
⑤ 用户与城市信息关系表:
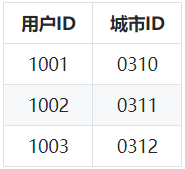
⑥ 用户与用户等级关系表:
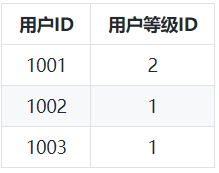
通过以上我们可以发现,范式建模就是将源表抽取为实体表,关系表,所以范式建模即是实体关系(ER)模型。数据没有冗余,符合三范式设计规范。
3. 使用 Kimball 模式建模
使用 Kimball 模式,需要将数据抽取为事实表和维度表,根据源表数据,我们将表拆分为:订单事实表,用户维度表,城市信息维度表,用户等级维度表。
① 支付成功订单事实表:
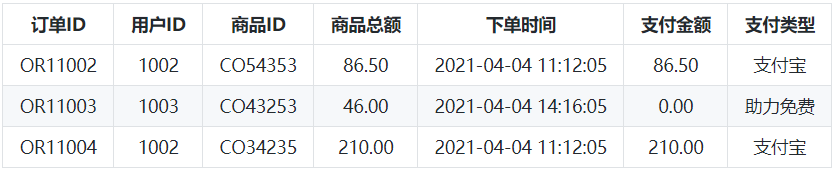
② 用户维度表:

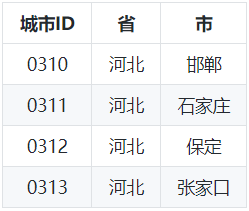
③ 城市信息维度表:
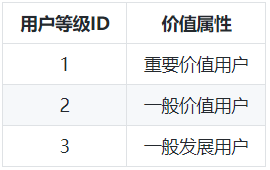
④ 用户等级维度表:
可以看出,在 Kimball 的维度建模中,不需要单独维护数据关系表,因为关系已经冗余在事实表和维度表中。
我们用图的方式将以上表之间的关系简单展示出来:
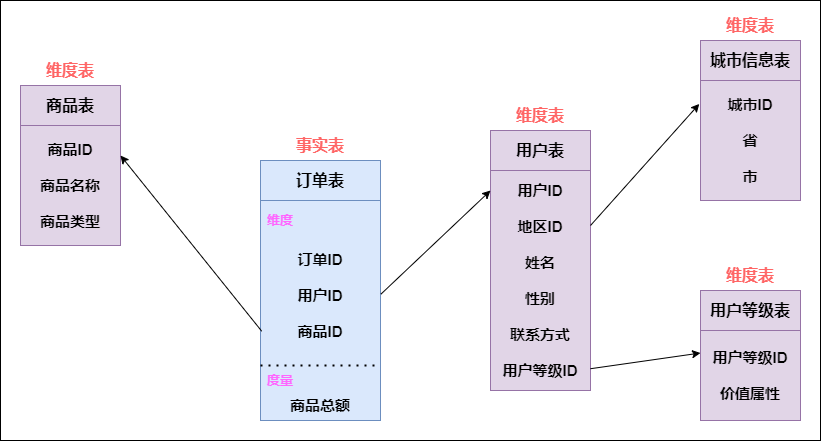
根据上图,我们发现什么,这不就是典型的雪花模式嘛,其特点就是维度表可以拥有其他维度表。
三、两种建模对比
两种建模方式特点
范式建模:通过上一小节的具体例子可以看出范式建模的优点:能够结合业务系统的数据模型,较方便的实现数据仓库的模型;同一份数据只存放在一个地方,没有数据冗余,保证了数据一致性;数据解耦,方便维护。但同时也带来了缺点:表的数量多;查询时关联表较多使得查询性能降低。
维度建模:模型结构简单,面向分析,为了提高查询性能可以增加数据冗余,反规范化的设计,开发周期短,能够快速迭代。缺点就是数据会大量冗余,预处理阶段开销大,后期维护麻烦;还有一个问题就是不能保证数据口径一致性,原因后面有讲解。
我们再来理解下维度建模:数据会抽取为事实-维度模型,维度就是看待问题的角度,从不同的角度看待某个问题,就会得出不同的结论,而要得到这个结论,就需要事实表中的度量,何为度量,就是事实表中数值类型的字段。
例:某公司的各个商品在全国各地市的销售情况,维度就是全国的城市和各个商品,度量就是商品的单价,从不同的维度计算销售额:如查看北京市酸奶的销售额,上海市纯牛奶的销售额,这就是不同的维度组合方式。在限定的维度条件上,计算商品单价的总和,也就是 sum 度量值,即可得到我们想要的结果。
维度建模,就是依靠维度进行建模,但是如果维度设计的不合理,会不会带来问题呢?
如果我们把省份当做一个单独维度,城市当做一个维度,计算城市的人口数量。这时省份和城市都是单独的维度,它们之间没有了关系,就会出现以下情况:
广东省 杭州市 1500
浙江省 广州市 1200
这时会出现数据口径不一致,最后导致数据结果不准确。而范式建模就不会出现这个问题,因为在范式建模中强调的就是实体-关系模型,所以省份和城市之间一定存在归属关系的,不会出现省份和城市口径不一致的问题。
所以,范式建模能保证口径的一致性,而维度建模不能!
建模方式对比
通过上一节的具体的例子以及两种建模的特点,我们对比下两种建模方式的不同:
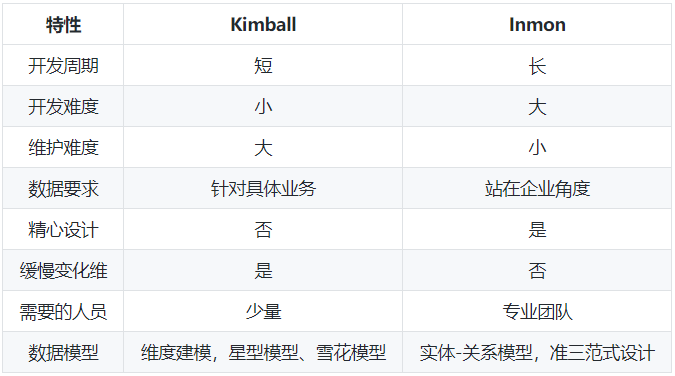
我们知道,互联网公司的业务一般是周期比较短需求变化快,并且迭代频繁,如果精心设计 Inmon 实体-关系的模式似乎并不能满足快速迭代的业务需要。所以,互联网公司更多场景下趋向于使用 Kimball 维度-事实的设计反而可以更快地完成任务。
四、两种建模混合场景
通过以上几个小节我们已经理解了范式建模与维度建模的思想以及它们之间的异同,优缺点。那么我们能不能将两种建模方式混合使用呢,让它们发挥各自最大的优势。接下来我们一起来看下。
范式建模必须符合准三范式设计规范,如果使用混合建模,则源表也需要符合范式建模的限制,即源数据须为操作型或事务型系统的数据。通过 ETL 抽取转换和加载到数据仓库的 ODS 层,ODS 层数据与源数据是保持一致的,所以 ODS 层数据也是符合范式设计规范的,通过 ODS 的数据,利用范式建模方法,建设原子数据的数据仓库 EDW,然后基于 EDW,利用维度建模方法建设数据集市。
结合两种建模方式的各自规范,混合建模按照“松耦合、层次化”的基本架构原则进行实施。混合数据仓库架构方法主要包含以下关键步骤:业务需求分步构建、分层次保存数据、整合原子级的数据标准、维护一致性维度等。
最后
建模方式没有好与坏之分,只有合适与不合适之分,在实际数仓建设中,需要灵活多变,不能全依赖建模理论,也不能不依赖。适时变通,才能建设一个好的数据仓库。
