
在实施Qlik Sense架构时,我们强烈建议您实施语义层( Semantic Layer),在Qlik中称为QVD层。
QVD层充当集中式数据库,其中包含从一个或多个数据源提取产生的一组受控数据快照。 Qlik数据库中的数据应当为“业务就绪”的,这意味着它应该是干净的,及时的,可访问的,格式化且易于关联的,使这些数据非常适合真正的自助服务分析。
QVD层数据文件以“ .QVD”文件扩展名存储。 QVD文件可用于诸多目的,至少可以很容易地识别出以下四个主要用途:
1.增加加载速度
对于大型数据集,脚本执行将变得相当快。
2.减少源系统上的负载
从外部数据源获取的数据量可以大大减少。 这样可以减少外部数据库和网络流量上的负载。 此外,当多个应用共享相同的数据时,只需将其从源数据库加载到QVD文件一次即可。 其他应用可以通过此QVD文件使用相同的数据。
3.整合来自多个应用程序的数据
可以将来自不同业务部门的类似数据合并到一个位置。
4.增量加载
通过从不断增长的数据库中加载新记录,可以将QVD功能用于增量加载。
Qlik Sense的两层架构
在大多数情况下,使用Qlik Sense时,会采用两层架构的方法,因为它可以带来简单化,高性能和更高的敏捷性。 由于敏捷性的特点,我们认为它最能实现自助式的分析服务环境。
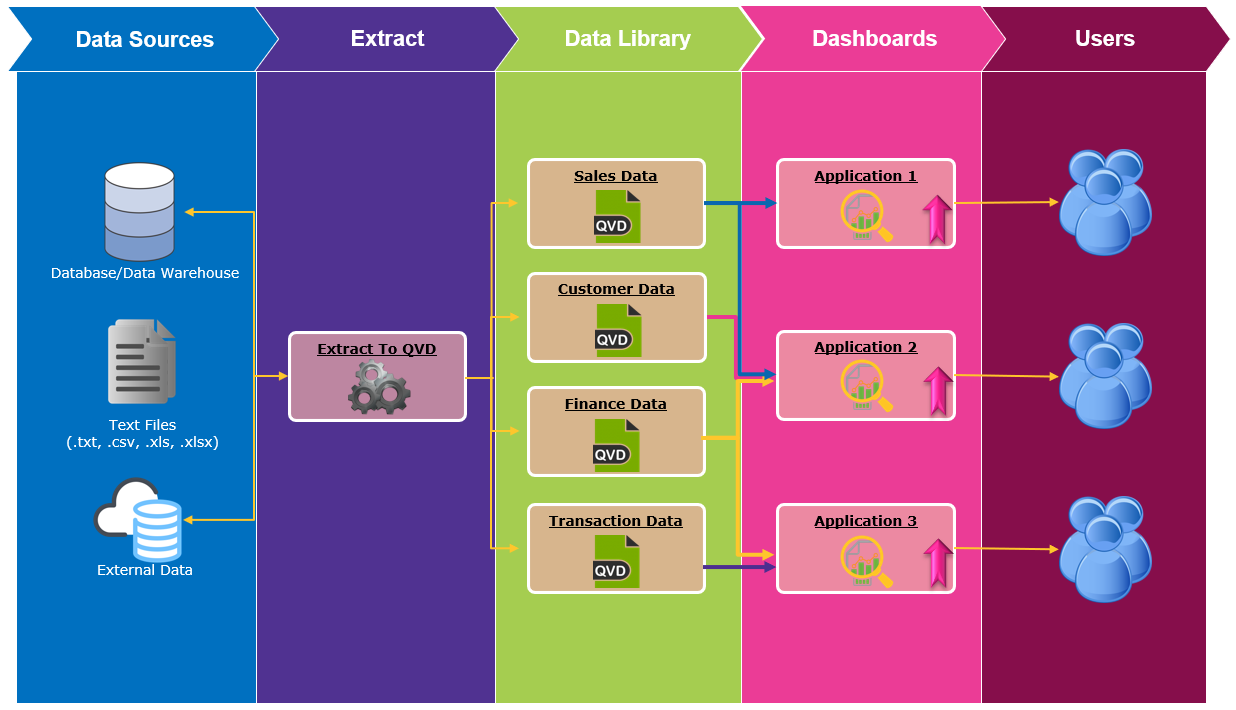
Qlik Sense的两层架构
总体而言,两层体系结构将会产生一个或多个Extract应用程序。 Extract应用程序是不包含任何可视化用于报告目的的应用程序。 他们只需连接到所有必要的数据源,提取原始数据,将数据转换为可用于业务的格式,然后将其存储到.qvd文件管理器中即可。 您可以根据业务更新和不同数据源的更新速度,将提取应用程序拆分为多个应用程序。 每个QVD都包含一个数据表,用于在UI应用程序(仪表板)中的报告。 创建数据库后,用户可以使用受管控的数据创建UI应用程序。 由于QVD已准备就绪,因此用户可以使用数据管理器简单地导入转换后的数据,并且不需要使用脚本开发: 相应的关联关系已经由开发人员定义,因此它们会自动关联。
Qlik Sense的三层架构
Qlik Sense的三层体系结构往往在大型企业中较为常见。 这也是Qlik View中的常见做法,如果您打算将Qlik Sense用于指导性分析,则此方法可能更加适合。
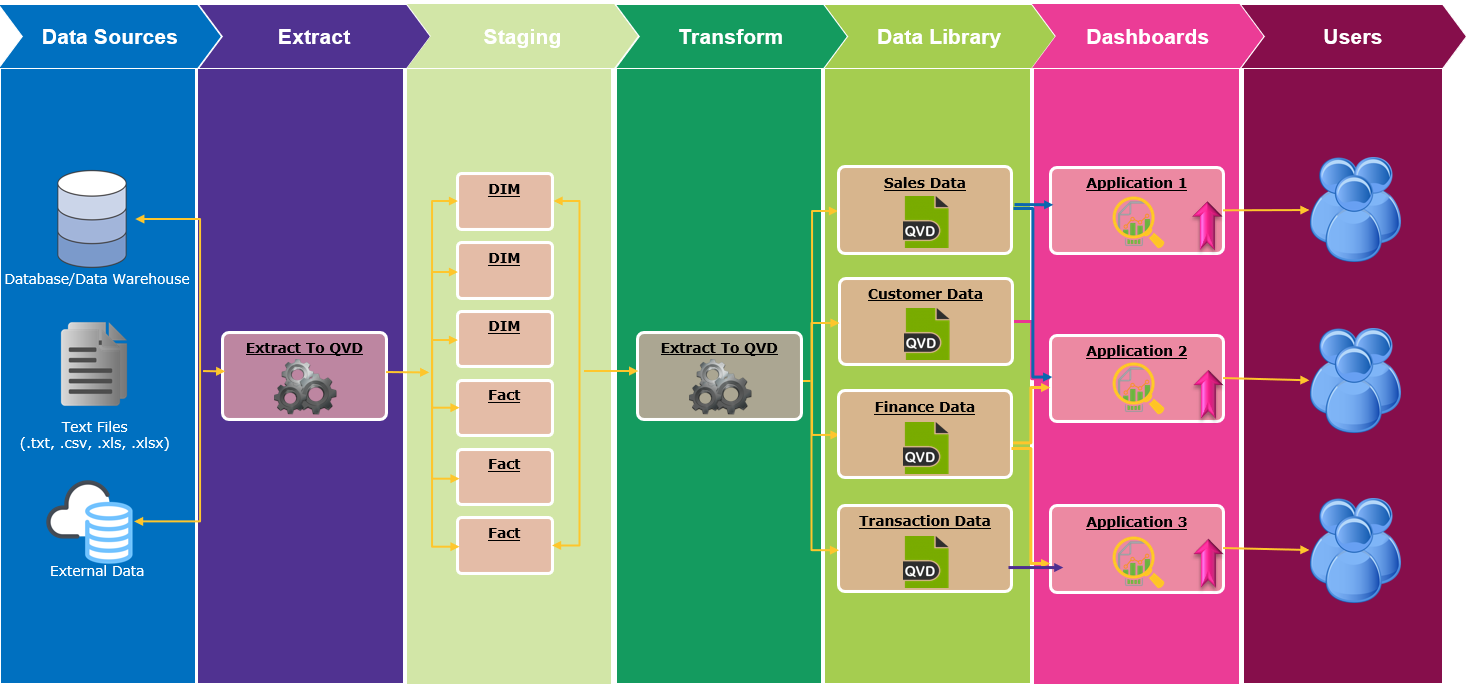
Qlik Sense的三层架构
三层体系结构的工作方式与两层结构几乎相同,不同之处在于提取和转换过程将分为两个单独的步骤。 三层方法将利用一个或多个应用程序来提取原始数据,但不会执行任何转换,它只是查询信息并将其存储到QVD中。 通过最小化连接时间,这减少了对实时数据源的影响。 一旦创建了初始(分段)QVD,我们就可以继续应用所需的任何转换,以使数据适合于报告和仪表板。 所有转换仅在Qlik环境中进行,然后存储到业务就绪的QVD中。
以上仅为从层次角度对Qlik Sense架构的分析,有关使用QVD以及报告的实现任需更多的架构分析。
